

How 100% Test Coverage Still Kills People

A few years ago, in 2018 and 2019, two Boeing 737 MAX airplanes fell out of the sky and killed everybody on board. In both cases, a piece of software was quickly implicated as part of the chain of events that caused these accidents. If aircraft software is among the best engineered and tested and regulated in the world, how is it possible that it still fails catastrophically? And why didn’t testing catch any of these problems?

Welcome to Testing Gold. What we want to do here is rattle our own cage a bit in the practices of software engineering and software testing and find out what works and what doesn’t work.
Now, the Boeing incident is a really good example of why software fails and why it sometimes fails catastrophically. But rather than make a beeline for the story and just tell you what happened, I want to give you a bit of context of why this is so in principle—why software fails, why it is buggy, and why testing is struggling to cover all the angles.
The Difficulty of Exhaustive Testing
The answer generally lies with the principle stating that exhausting testing is not possible. It is one of the seven testing principles. And what it really says is that, in all but the most trivial of software, it is literally not possible to test everything that can happen.

Now, this is an empirical principle, meaning that it was formulated based on experience, but there are a number of arguments that back this up. And pretty much all of them have to do with complexity—not just of the technology itself, but also of the way it’s created and of the real-world conditions that it typically operates under.
So, what are these forces acting on our code?
Let’s take a look.
The Complexity of Software
The first thing we would have to say about the code is that it doesn’t really exist in a technology bubble. It’s part of a human creation process of the software delivery lifecycle, where we have requirements, we have handovers, and we have a ton of opportunities for failure right there.
And then the next thing, of course, is that no software runs by itself. It runs on what we can call the stack. It’s other software—essentially libraries, packages, frameworks, compilers, runtime environments, server software, operating systems, any kind of abstraction layers like virtualization, as well as distributed software, all the way down to embedded software that runs on the hardware level. Not to mention all the tooling that we need to produce and deploy and maintain it.
Then, in addition to that, of course, there’s the hardware, and the network, and the periphery, and everything else that it runs on.
Then there’s the ecosystem of integrations—i.e. other applications and services that it functions with. And on a wider scale, of course, the internet, with its constant evolution. For instance, in the diversity of all the consumer devices that are out there, the Internet of Things (IoT), the threats posed by viruses, and bots, and AI, and all of that.
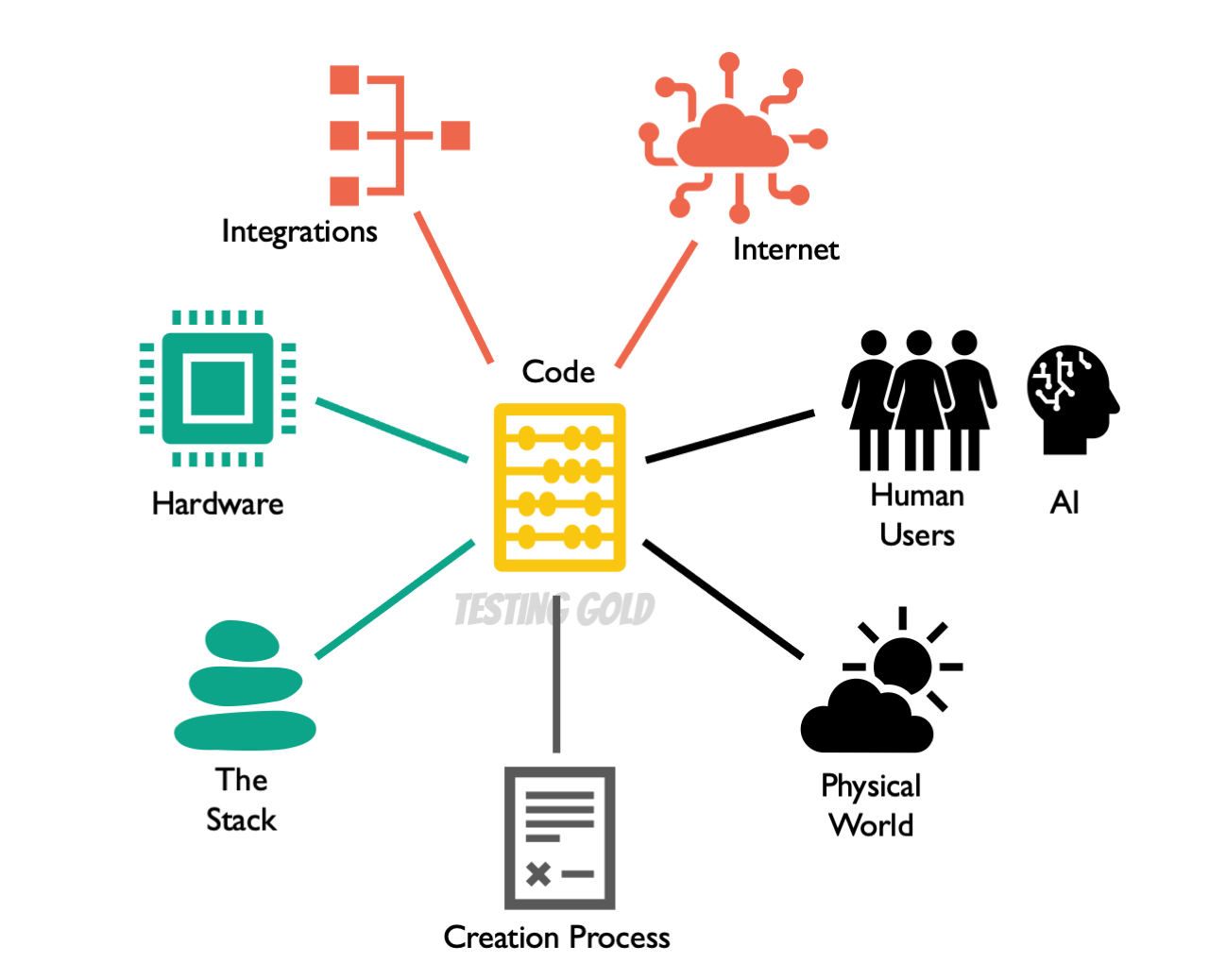
Next up, human users. I think that one’s kind of obvious, and I think we can stop talking about that right there.
But then there’s also something that people generally don’t think about, which is the physical environment that software has to operate in. That includes things like temperature, humidity, erosion, radiation, visibility conditions, physical obstacles.
And finally, because we’re in the 21st century, we also have to add AI now to the picture.
All of this interconnects, and it comes with complexity, and with variety, and with opportunity for failure at every angle. And it’s virtually uncontrollable.
With that in mind, let’s take a look at our Boeing 737 MAX story.
The Business Situation
Now, the story starts with a business situation.
In the early 2010s, Boeing and Airbus were neck and neck in the sort of mid-sized, middle-distance segment, which is quite important for their business. Then Airbus came out with a better plane. They had the A320 neo, which was more fuel-efficient, so they had an edge in the market.
Boeing had to respond, and because it takes time to build a new airplane from scratch, they took an existing airframe—their old workhorse, the Boeing 737—and they fit more fuel-efficient but bigger engines onto it.
Now, the problem with that was that, under rare conditions, they found that this changed the flight characteristics of the aircraft. And it would produce an effect where the nose of the plane would pitch up, which is dangerous because the aircraft can stall. They decided to deal with that by putting software on board to fix the problem and autocorrect this condition when it occurs.
The Software
This system is called MCAS and it was an automated flight control system of sorts.
The way this works is that they have two sensors at the nose of the plane that would detect the so-called angle of attack and therefore register the plane’s aspect based on the airflow against them. There are two of them because they are potentially vulnerable to physical conditions like weather or maintenance problems. So they can, under rare conditions, malfunction.
The software monitors these sensors, and when an undesired nose-up event would occur, it would correct the situation without the pilots having to do anything.
Now, all of that sounds pretty helpful. You have an automated system on board that corrects the problem, especially if the pilot knows that it’s there and that they’ve been trained for this situation.
The Human Factor
However, training pilots costs the airlines quite a bit of money. So Boeing figured that with the additional cost, they would lose their edge in the market.
So they came up with a way that they didn’t really have to declare the MCAS as a new feature, but simply as a relatively minor improvement to something that was already there on an existing airframe. This would allow them not to have to train the pilots and also to curiously exclude this feature altogether from the onboard manual as a sort of an under-the-hood system that the pilots didn’t need to know about.
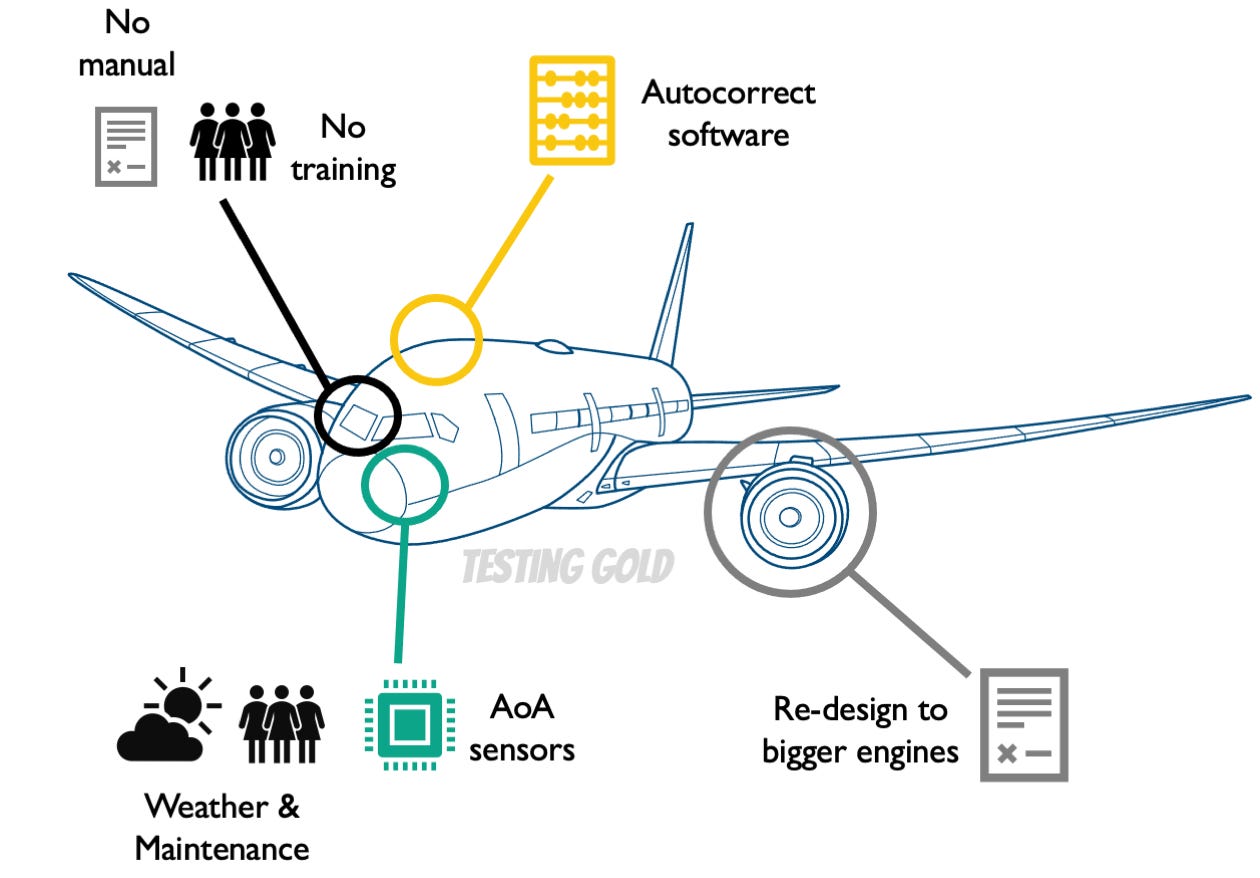
Now, there is, of course, regulation in place, and they couldn’t just really do that without backing up the decision with design documentation, with risk and failure analysis, and, of course, with the result of tests.
Now, this is where we get to testing.
The Test Scenarios
Now, we’ve seen the complexity of factors in play here. So how was all of this considered in design, in execution, and in testing. And how did it ultimately fail?
Let’s start by looking at the aircraft and the software and put up some basic test scenarios.
What we’re looking at as our inputs are a) the aircraft itself and then b) the two sensors that tell us something about it. Then the expected result is what the software does to react to those conditions.
The first case is our success path (1). The input conditions are that we experience this rare nose up event in the airframe and our two sensors correctly detect all of this. The expected result is that software reacts to that, points the nose down, and controls the situation.
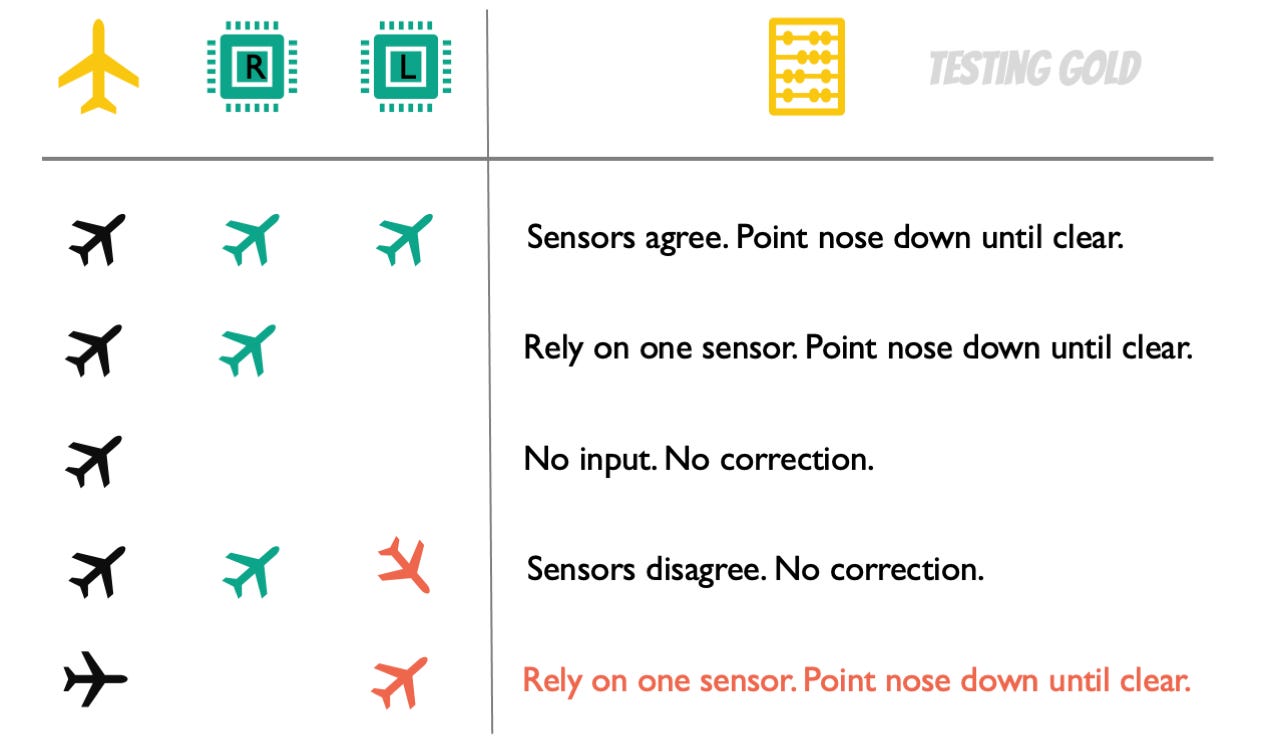
But we also have to deal with exception paths. So, what happens if one of the sensors is offline (2)?
We mentioned that they’re potentially vulnerable to weather conditions. In this case, the expected result is that the software relies on the single available sensor. It will pick up the correct signal and it will point the nose down and correct the condition. Everything is good. Now, but what about if both sensors are down (3)?
In this case, the software doesn’t receive any input. It cannot react for obvious reasons. In this situation, we would rely on the pilot to notice the nose up event and correct this manually.
But sensors cannot just be offline. They can also be malfunctioning. What if we have disagreeing sensors (4)? What if we have one correctly noticing the nose up event and the other one either not noticing or telling us the exact opposite, that the nose is pointing down?
In this case, the software is programmed not to do anything, because it doesn’t have reliable input. Again, we’re in a situation where the pilot would have to notice the nose-up condition and then manually correct it.
But what if both of these exception conditions occur at the same time? So, one offline and one lying to us (5).
Imagine the airplane is in level flight and we don’t have a problem, but one of the sensors is down, and the other one is telling us that we have a nose-up event (when, in fact, we don’t). In this case, we recall that the software is programmed to react to the single online sensor, and the expected results is that it points the nose down until the condition is rectified. But because our sensor is malfunctioning, you’re never going to see this positive feedback. The software is damned to point the nose down, and down, and down, and you can see where this is going …
The Risk Assessment
Now, as I mentioned, Boeing had to do risk analysis about this; what is called a functional hazard analysis. For this, they are looking at impact and likelihood of all these scenarios.
So, for our success scenario (1) here, based on what we know about the engines and the flight characteristics, we assume that this is already a rare case. Under normal flight conditions, this doesn’t even happen. When a nose-up event does happen, and both our sensors are functioning, and the software correctly corrects the problem, the impact is zero. The pilots don’t even notice that this is happening because the software is automatically correcting the problem.
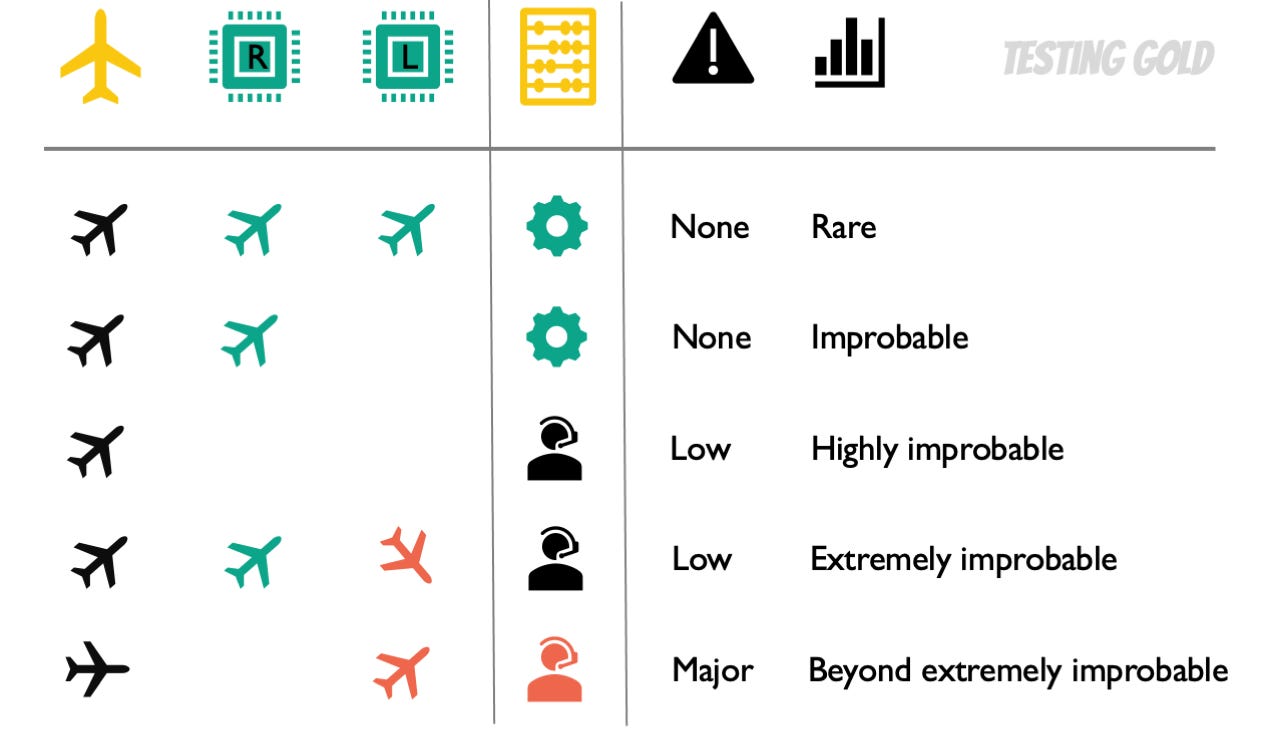
The same when we have a single sensor (2). And this scenario is even less frequent, because in addition to the rare nose-up event, we now we have another rare event, which is an offline sensor. And together, they’re being considered improbable.
Similarly, when we have both sensors knocked out (3), this is now considered highly improbable. And the impact is still low because the pilots would notice the condition and would be able to manually correct it.
Even more improbable is that we have a malfunctioning sensor that tells us the opposite; our disagreeing sensors (4). It’s a really, really very rare error condition indeed. And again, the impact would be low here because the software would do nothing and the pilots have an opportunity to manually correct.
Now, for our last condition, the Boeing people did recognize that this would have more of a major impact because now we have a single, lying sensor (5), and the software auto-correcting when there is no correction necessary and pointing the plane down. In this case, the pilots are expected to go through a series of steps to turn the system off and point the nose back up. This was considered beyond extremely improbable because of the confluence of all these extraordinary conditions that would have to come together to produce it.
But now we know also that the pilots didn’t know the system was on board, and that they were not trained for it, and that it wasn’t in the manual.
It was later found in the investigation that the pilots had only about 10 seconds to perform the right steps in the right order to rectify the situation; and this, while the software is pushing the plane down, and the controls are fighting them and the alerts are screaming at them.
So when this event happened that was deemed beyond extremely improbable, pilots were unaware, they were untrained, they were confused and they made mistakes and they didn’t regain control over the aircraft.
The Lesson
So what do we learn from all of this?
When I teach testing, I often open up with an example exactly like this. Because what I want everybody to understand is that we cannot just focus on what we control. If we only focus on what we control—the code, the tooling, the environments, the infrastructure—we’re often really only seeing a part of the problem.
It doesn’t matter what we’re working on, whether this is a mobile app, or enterprise software, or the control system of a self-driving car. To get quality into any kind of software, you need to consider what it is that makes it fit for purpose. And in most cases, that means that it needs to function in a complex environment of technical, human, and real-world factors. And as we pointed out, exhaustive testing of that is not possible.
But what is possible is a proper risk awareness, a sense of danger. Just like in this case, where the Boeing engineers were aware of the scenario but not of all its implications, like the lack of training, or the software not even being in the manual. And so they made the wrong call and people died.
So again, we cannot just focus on what we control, the tickets, the code. It’s our job to see the whole picture and to consider what needs to be done about it. How we can prevent failures, and how we can engineer and test for them really requires a holistic approach and a risk-aware one. And that’s a complex skill set. It’s not a trivial thing.

Final Words
In this series, we’ll be talking about this quite a bit. And hopefully you stick around and subscribe to my Substack (and the corresponding YouTube channel). And do let me know what you think in the comments.
And I’ll see you next time on Testing Gold.
Note: you can find all the details of the case in the final report for one of the accidents released by Indonesia's National Transportation Safety Committee (KNKT).
All images by the author except monochrome plane generated by Gemini.